openHistorian
Efficient, low-cost storage of time-series data.

- Lossless compression for quick and efficient storage
- Time precision down to 100 atto seconds
- Support for multiple data types
- Alarming and notification Services
- Device availability and correctness reporting
- Dynamic expression-based calculations for new values, alarms and notifications
- Community Support
- Dedicated Support
- Dedicated 24/7 Support Available
- Lossless compression for quick and efficient storage
- Time precision down to 100 atto seconds
- Support for multiple data types
- Alarming and notification Services
- Device availability and correctness reporting
- Dynamic expression-based calculations for new values, alarms and notifications
- Community Support
- Dedicated 8x5 Business Day Support
- Dedicated 24x7 Support Available
openHistorian
The openHistorian is a back office system designed to efficiently archive SCADA, synchrophasor and other process control data to support real-time grid operations and post-operation analysis. The openHistorian is optimized to store large volumes of time-stamped data quickly and efficiently.
The openHistorian supports timestamps with up to atto (10-16) second precision -- significantly more precise than GPS time-stamps. The openHistorian also implements lossless data compression resulting in small data storage requirements while retaining all the nuances in the data. While lossless compression rates vary based on the nature of the processes monitored, as a rule of thumb about 424 million floating point values are saved per GB of storage. This means, for example, that a SCADA system with 50,000 points to be archived every 2 seconds would fill a 3 TB hard-drive about every 600 days. Or for example, a synchrophasor data system with 100 PMUs reporting 30 times per second would fill a 3 TB hard drive about every 320 days.
The openHistorian also includes numerous TSL Adapters that are available through the Grid Solutions Framework.
The openHistorian leverages the GSF SNAPdb Engine - a key/value pair data archival technology developed to significantly improve the performance of both data insertion and data retrieval to enable the openHistorian to become the low-latency data layer for real-time applications. The openHistorian is a time-series implementation of the SNAPdb engine where the "key" is a tuple of time and measurement ID, and the "value" is the stored data which consists of both data and its associated flags.
The openHistorian comes with a high-speed API that interacts with an in-memory cache for low-latency extraction of near real-time data. The hive files produced by the openHistorian are ACID Compliant to create a durable and consistent file structure that is resistant to data corruption. Internally, the data structure is based on a B+ Tree that allows out-of-order data insertion.
Three data-management utilities are available to assist in using the openHistorian. They are automatically installed alongside the openHistorian:
- Data Migration Utility - Converts openHistorian1 / DatAWare Archives to openHistorian2 Format.
- Data Trending Tool - Queries Selected Historical Data for Visual Trending Using a Provided Date/Time Range.
- Data Extraction Utility - Queries Selected Historian Data for Export to a CSV File Using a Provided Date/Time Range.
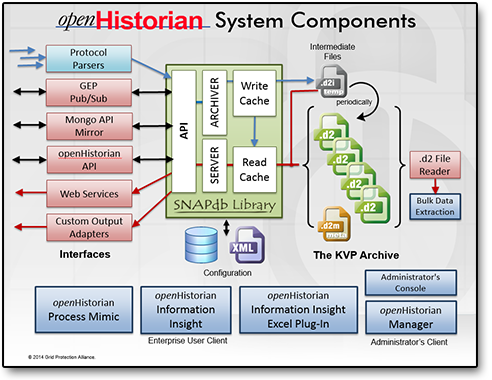
openHistorian
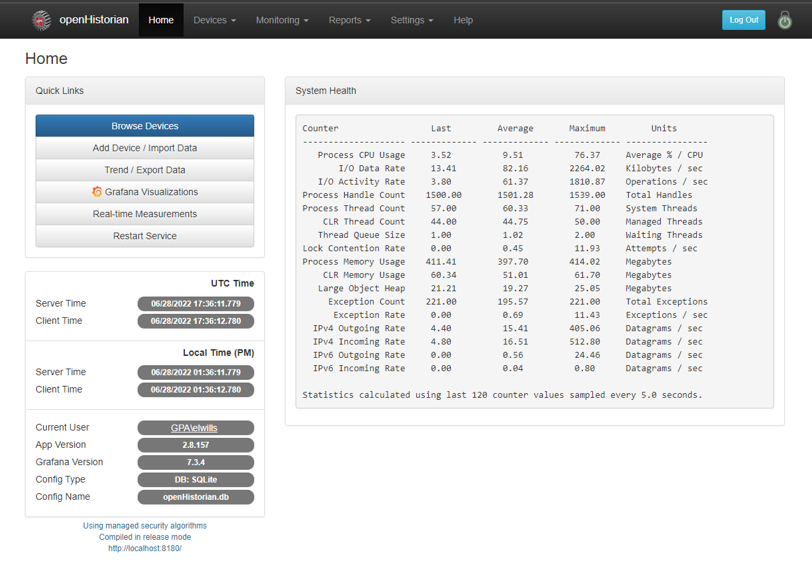
The openHistorian provides a web interface for analysis of real-time and archived data.
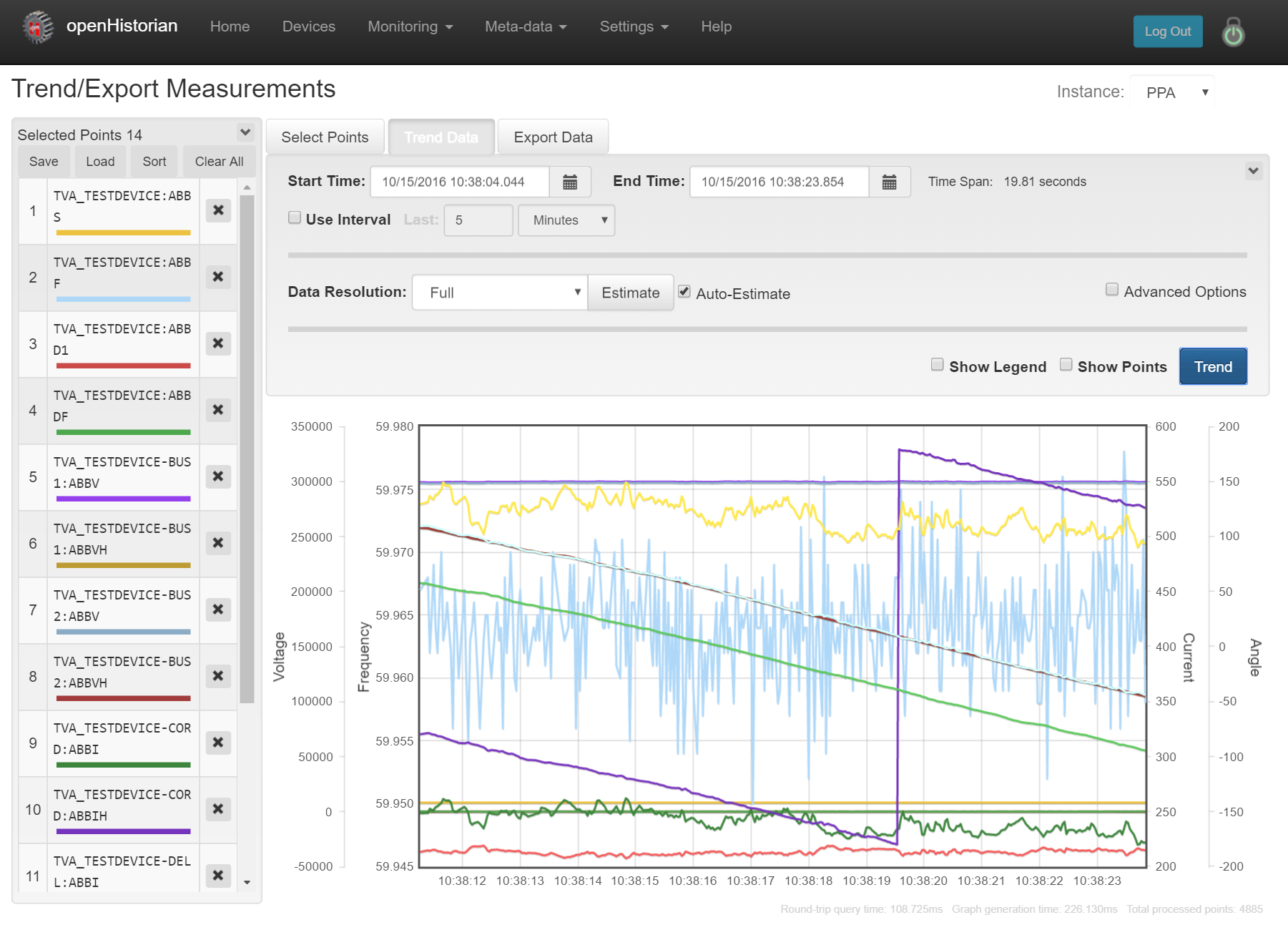
Historical Trends
View the trends in your archived data.
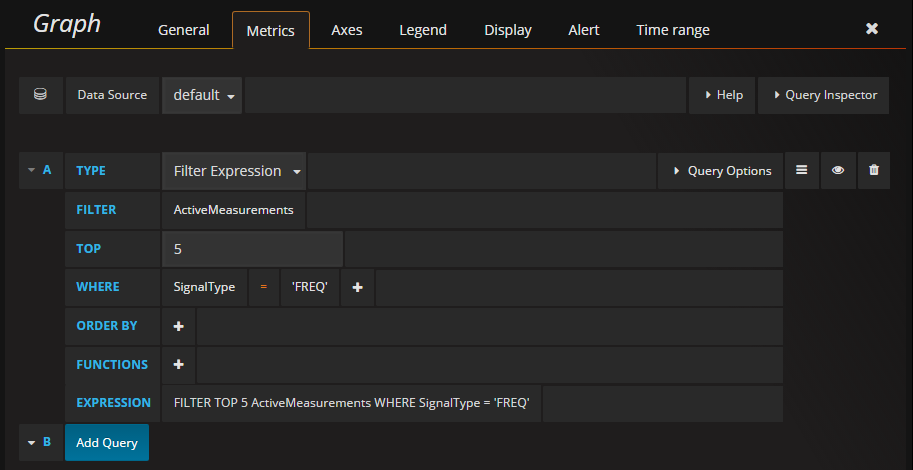
Grafana Visualizations
The openHistorian web interface includes Grafana plugins to query and view your data.